
Cliquez sur les questions ci-dessous pour en savoir plus au sujet de Loterre
Loterre (acronyme pour Linked open terminology resources) est une plateforme d’exposition et de partage de terminologies scientifiques multidisciplinaires et multilingues.
S’appuyant sur un triplestore, elle se veut conforme aux standards du web des données ouvertes et liées (LOD) ainsi qu’aux principes FAIR, qui visent à rendre les données Faciles à trouver, Accessibles, Interopérables, Réutilisables.
Les terminologiques disponibles dans Loterre peuvent répondre à des besoins de fouille de texte, d’annotation sémantique, de recherche d’information ou de traduction.
L’accès aux ressources de Loterre est ouvert à tous, l’utilisation ultérieure de chacune d’elle étant liée à la licence qui la régit.
Loterre donne accès à des ressources terminologiques scientifiques et permet :
Cette vidéo montre un exemple d’utilisation d’une terminologie hébergée dans Loterre, pour les traducteurs :
Loterre offre également des services en ligne, dont le contenu est détaillé dans le paragraphe « Services proposés dans Loterre » de cette page.
Le site Loterre n’est pas réservé aux seules ressources terminologiques produites par l’Inist. Il peut offrir ses services d’exposition à d’autres producteurs de données terminologiques qui en feraient la demande via le formulaire de proposition.
Les producteurs intéressés sont invités à prendre connaissance de la Charte de Loterre.
Les principes FAIR (Findability, Accessibility, Interoperability, Reusability) applicables aux données scientifiques ont été énoncés par Force11 et publiés par Wilkinson et al. en 2016 (The FAIR Guiding Principles for scientific data management and stewardship). Les étapes de la FAIRification ont été explicitées par GO FAIR .
Ces principes forment un guide de bonnes pratiques pour la gestion et la réutilisation des données et des métadonnées par les machines comme par les humains. Cependant, ils ne constituent pas une spécification car ils ne préconisent ni standard, ni technologie, ni format de données particulier.
De plus, les données FAIR ne sont pas obligatoirement « open » et peuvent présenter différents degrés de FAIRisation et/ou d’ouverture. Il ne faut donc pas confondre LOD (basé sur des standards du web sémantique) et FAIR (basé sur des principes) : voir à ce sujet “Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud” (2017)
Les (méta)données terminologiques exposées dans Loterre répondent à l’ensemble des principes FAIR. En effet elles sont :
Elles peuvent également participer à la FAIRisation des (méta)données de la recherche en favorisant leur interopérabilité sémantique (par les concepts des vocabulaires ou des thésaurus).
De même, les services Contrôler, Transformer et Aligner visent à faciliter la création et l’enrichissement de terminologies en format SKOS/RDF-XML selon les pratiques FAIR.
Loterre et les terminologies de l’Inist que la plateforme héberge sont signalées dans le portail FAIRSharing : https://fairsharing.org/collection/Loterre
Loterre se veut conforme aux principes du LOD (Linked Open Data) tels qu’ils ont été présentés en 2006 par le W3C (Tim Berners-Lee) : les ressources terminologiques sont ici considérées comme des ensembles organisés de termes (désignant des concepts) qui sont des jeux de données librement accessibles via les technologies du web sémantique.
Le Linked Data ou « web des données liées » repose sur 4 règles de base :
En ajoutant des licences ouvertes pour la diffusion et la réutilisation des ressources publiées sur le web, Loterre respecte les règles du « Linked Open Data ».
T. Berners-Lee (2010) a d’autre part proposé un classement progressif des LOD avec 5 étoiles selon les critères suivants :
* Données librement disponibles sur le web, avec mention d’une licence ouverte
** Données dans un format structuré, lisible par la machine
*** Formats non propriétaires (CSV, JSON…)
**** Standards ouverts W3C (RDF, XML, SPARQL) et URI comme identifiant de ressource
***** Données reliées à d’autres données RDF via des alignements dans le LOD Cloud
Enfin, les ressources intégrées au triplestore RDF se veulent, autant que possible, conformes aux bonnes pratiques du W3C relatives à la publication de données liées (W3C, 2014).
Toutes les ressources exposées dans Loterre sont compatibles avec ces règles et principes et peuvent être classées 4 ou 5 étoiles :
Outre le téléchargement des terminologies hébergées, Loterre propose des services destinés à tout producteur de terminologie, qu’il souhaite ou non exposer ses ressources dans Loterre.
Les services Contrôler, Transformer et Aligner visent à faciliter la création et l’enrichissement de terminologies en format SKOS/RDF-XML selon les principes FAIR (Facile à trouver, Accessible, Interopérable, Réutilisable).
n.b. : Les données utilisateurs traitées par ces services ne sont pas conservées par l’Inist-CNRS.
Ce service permet d’aligner (mettre en correspondance) un fichier SKOS/RDF-XML valide (source) avec une ressource terminologique de Loterre (cible) spécifiée par l’utilisateur.
Ce service vérifie si un terme (forme préférentielle ou synonyme) d’un concept A du vocabulaire source est identique à un terme (préférentiel ou synonyme) d’un concept B du vocabulaire cible (pour un même code langue). Il traite fichiers contenant des « skos:Concept » (forme courte de la syntaxe RDF/XML) ou des « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] » .
A noter que l’alignement repose sur une comparaison de chaînes de caractères, qui doivent être identiques de part et d’autre, sans tenir compte du contexte ; les alignements devront donc être validés par l’utilisateur.
2 variantes de ce service sont proposées :
Les enregistrements du fichier d’alignements peuvent être ajoutés tels quels au début ou à la fin du fichier source.
Le service « Annoter » permet de rechercher, dans une portion de texte écrit en français, anglais ou espagnol, la présence de termes (labels préférentiels et synonymes) d’une terminologie hébergée dans Loterre.
Il renvoie le texte dans lequel les termes détectés ont été surlignés et un tableau des termes et des concepts correspondants, avec leur URI.
Le service « Contrôler » permet de vérifier en ligne la validité d’un fichier terminologique enregistré en format SKOS.
Trois types de contrôles sont proposés : validité des collections, validité des concepts, validité du schéma de concepts.
Le code couleur des anomalies détectées correspond à leur degré de gravité :
| code sur fond rouge | anomalie critique |
| code sur fond orange | anomalie majeure |
| code sur fond jaune | anomalie mineure |
Le service « Contrôler un fichier SKOS/RDF-XML au niveau des collections » traite des fichiers contenant des éléments de type « skos:Collection » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]] » ou des « rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]] »
Il réalise en premier lieu une analyse de la ressource pour déterminer :
Il opère ensuite les contrôles et renvoie les résultats sous la forme d’une table détaillant les types d’anomalies détectés.
Liste des contrôles effectués :
| Code | Description de l’anomalie |
|---|---|
| Col-0 | La ressource ne contient ni skos:Collection ni rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]] ni « rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]] ». |
| Col-@0 | Absence d’uri (identifiant) au niveau de la collection. |
| Col-@N | Présence d’un attribut non autorisé. Seul l’attribut « rdf:about » est autorisé pour « skos:Collection » ou rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]] ou rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]]. |
| Col-2 | Anomalie de structuration des collections. En dépit de la présence d’une propriété « isothes:superGroup » au niveau des collections, aucune propriété « isothes:subGroup » n’a été détectée au niveau de la super-collection correspondante. Utiliser la transformation « Insérer les collections spécifiques dans un fichier SKOS/RDF-XML valide » pour y remédier. |
| Col-3 | Le contenu de l’attribut « rdf:resource » de la propriété « skos:inScheme » des collections est différent de l’identifiant de la ressource (ConceptScheme). |
| Col-4 | Un membre d’une collection est inexistant dans la ressource. Créer le concept correspondant ou supprimer ce membre. |
| Col-5 | L’uri de la collection contient un caractère non autorisé (espace, apostrophe, quote, crochet gauche, crochet droit). |
Le service « Contrôler un fichier SKOS/RDF-XML au niveau des concepts » traite des fichiers contenant des éléments de type « skos:Concept » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] »
Il réalise en premier lieu une analyse de la ressource pour déterminer :
Il opère ensuite les contrôles et renvoie les résultats sous la forme d’une table détaillant les types d’anomalies détectés.
Liste des contrôles effectués :
| Code | Description de l’anomalie |
|---|---|
| D-Id | Contrôle d’unicité de l’identifiant de chaque concept. Deux concepts ne peuvent pas avoir le même identifiant. |
| E-0 | Présence d’un élément (propriété) vide. Peut nuire au bon déroulement de la suite du programme de contrôle. Peut également empêcher l’import dans certains éditeurs terminologiques. |
| @-0 | Présence d’un attribut vide au niveau d’un élément. |
| R-A1 | Présence d’un conflit au niveau des relations : un même concept est à la fois concept associé et concept générique du concept courant. |
| R-FX1 | Présence d’une relation hiérarchique reflexive : un concept est générique de lui-même. |
| R-FX2 | Présence d’une relation associative reflexive : un concept est associé à lui-même. |
| R-31 | Présence d’un conflit à 3 au niveau des relations hiérarchiques et associatives : si un concept A a comme concept spécifique un concept B et qu’il est associé à un concept C, le concept C ne peut pas être un concept spécifique du concept B car le concept C ne peut pas être lié simultanément au concept A par deux relations disjointes « skos:narrowerTransitive » et « skos:related ». Voir détails dans SKOS-Primer. |
| R-32 | Présence d’un conflit à 3 au niveau des relations hiérarchiques et associatives : si un concept A a comme concept générique le concept B et qu’il est associé à un concept C, le concept B ne peut pas avoir comme concept générique le concept C car ce dernier ne peut pas être lié simultanément au concept A par deux relations disjointes « skos:broaderTransitive » et « skos:related ». Voir détails dans SKOS-Primer. |
| R-B3 | Présence d’une boucle : un concept est à la fois concept spécifique et concept générique du concept courant. |
| R-A2 | Présence d’un conflit au niveau des relations : un concept est à la fois concept spécifique et concept associé du concept courant. |
| R-NS | Relation associative (skos:related) non symétrique. |
| R-0 | Une relation (générique, associative ou spécifique) est établie avec un concept inexistant. |
| R-OR | Concept orphelin : un concept qui n’est pas un top-concept et qui n’a ni générique ni spécifique. |
| CS-0 | Absence de rattachement du concept à la ressource via la propriété « skos:inScheme ». |
| CS-3 | Le contenu de l’attribut « rdf:resource » de la propriété « skos:inScheme » est différent de l’identifiant de la ressource. |
| LP-0 | Préférentiel absent pour une des langues de la ressource. |
| LP-N1 | Plusieurs libellés préférentiels d’une même langue pour un même concept. |
| LP-LA1 | Doublon libellé préférentiel / libellé alternatif au sein du même concept. |
| LP-LC1 | Doublon libellé préférentiel / libellé caché au sein du même concept. |
| LP-LP2 | Libellé préférentiel identique pour deux concepts différents. |
| LP-LA2 | Doublon libellé préférentiel / libellé alternatif entre deux concepts différents. |
| LP-LC2 | Doublon libellé préférentiel / libellé caché entre deux concepts différents. Les cas sont signalés. |
| LA-LA1 | Doublon au niveau des libellés alternatifs au sein du même concept. |
| LA-LA2 | Libellé alternatif identique pour deux concepts différents. |
| LA-LC1 | Doublon libellé alternatif / libellé caché au sein du même concept. |
| LA-LC2 | Doublon libellé alternatif / libellé caché entre deux concepts différents. Les cas sont signalés. |
| LC-LC1 | Doublon au niveau des libellés cachés au sein du même concept. |
| LC-LC2 | Libellé caché identique pour deux concepts différents. Les cas sont signalés. |
Le service « Contrôler un fichier SKOS/RDF-XML au niveau du schéma de concepts » traite des fichiers contenant des éléments de type « skos:ConceptScheme » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#ConceptScheme’
Il réalise en premier lieu une analyse de la ressource pour déterminer :
Il opère ensuite les contrôles et renvoie les résultats sous la forme d’une table détaillant les types d’anomalies détectés.
Liste des contrôles effectués :
| Code | Description de l’anomalie |
|---|---|
| CS-N | Elément ConceptScheme absent. Le fichier ne contient ni skos:ConceptScheme ni rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#ConceptScheme’]]. Le menu « Insérer un element ConceptScheme » peut être utilisé pour y remédier. |
| CS-0 | Absence d’uri (identifiant) au niveau de la ressource. |
| CS-1 | Présence d’un attribut non autorisé. Seul l’attribut rdf:about est autorisé pour l’élément ConceptScheme. |
| CS-2 | Absence de propriétés skos:hasTopConcept. En dépit d’une forte structuration de la ressource, le bloc ConceptScheme ne contient pas les propriétés skos:hasTopConcept pour lister les top-concepts. Le menu « Insérer les propriétés hasTopConcept dans un fichier SKOS » peut être utilisé pour y remédier. |
| CS-3 | Le contenu de l’attribut rdf:resource de la propriété skos:inScheme des concepts est différent de l’identifiant de la ressource. |
Le service « Transformer » permet de générer une terminologie en format SKOS-XML ou de convertir une terminologie initialement en format SKOS-XML dans un autre format.
Les opérations proposées par ce service peuvent être regroupées en trois types : correction, enrichissement et conversion.
Ces opérations sont en particulier destinées à corriger les anomalies préalablement détectées par le service « Contrôler ».
Le service « Supprimer les doublons au niveau des termes d’un fichier SKOS/RDF-XML » traite des fichiers contenant des éléments « skos:Concept » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] ».
Au niveau de chaque concept, ce service fonctionne de la manière suivante :
A l’issue de ce traitement, il convient de contrôler à nouveau le fichier en utilisant le service « Contrôler un fichier SKOS/RDF-XML au niveau des concepts », pour s’assurer qu’il ne subsiste plus de doublons.
Si un concept A est associé avec un concept B via la propriété « skos:related », le concept B doit lui aussi être associé au concept A via cette même propriété, car la relation est symétrique.
Le service »Corriger les anomalies de symétrie des concepts associés dans un fichier SKOS/RDF-XML » traite des fichiers contenant des éléments « skos:Concept » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] ».
Il insère dans le fichier SKOS la propriété « skos:related » manquante, lorsque la condition de symétrie définie ci-dessus n’est pas vérifiée.
A noter que ce traitement ne s’applique pas à d’éventuelles sous-propriétés de la relation « skos:related » (voir détails dans ce document).
La relation hiérarchique entre un concept A et un concept B est exprimée à l’aide de la propriété « skos:broader » et la présence au niveau du concept B d’une relation « skos:narrower » (qui en est la relation inverse) n’est pas obligatoire car elle est inférée de la relation « skos:broader ».
Cependant, le bon fonctionnement de certaines applications (comme Skosmos) nécessite la présence des deux relations.
Le service « Insérer les concepts spécifiques dans un fichier SKOS/RDF-XML valide » traite des fichiers contenant des éléments « skos:Concept » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] ».
Il insère dans le fichier SKOS, au niveau de chaque concept générique, autant de propriétés « skos:narrower » que de concepts spécifiques de ce concept.
La relation hiérarchique entre une collection A et une collection B est exprimée à l’aide de la propriété « isothes:superGroup » et la présence au niveau de la collection B d’une relation « isothes:subGroup » (qui en est la relation inverse) n’est pas obligatoire car elle est inférée de la relation « isothes:superGroup ».
Cependant, le bon fonctionnement de certaines applications (comme Skosmos) nécessite la présence des deux relations.
Le service « Insérer les collections spécifiques dans un fichier SKOS/RDF-XML valide » traite les fichiers contenant des « skos:Collection » ou des « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Collection’]] » ou des « rdf:Description[rdf:type[@rdf:resource=’http://purl.org/iso25964/skos-thes#ConceptGroup’]] ».
Il insère au niveau de la super-collection autant de propriétés « isothes:subGroup » que de collections spécifiques à cette collection.
Le service « Insérer un bloc ‘ConceptScheme’ dans un fichier SKOS/RDF-XML » traite les fichiers contenant des « skos:Concept » ou des « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] ».
Il insère deux blocs au début d’un fichier SKOS/RDF-XML :
– Un bloc « cc:License » avec par défaut la valeur de licence « Creative Commons CC-BY 4.0 ». Il convient de modifier ce bloc si la ressource est diffusée sous une autre licence.
– Un bloc « skos:ConceptScheme » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#ConceptScheme’]] » avec :
Après génération des champs, leur contenu textuel doit être complété et validé par l’utilisateur.
Le service « Insérer les propriétés « hasTopConcept » dans un fichier SKOS/RDF-XML valide » traite des fichiers contenant des « skos:ConceptScheme » ou des « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#ConceptScheme’]] ».
Il insère une propriété « skos:hasTopConcept » au niveau du bloc « ConceptScheme » pour chaque concept qui n’a pas de propriété « skos:broader ».
n.b. : Ne pas utiliser ce service pour les ressources non structurées ou faiblement structurées.
Le service « Insérer les propriétés « topConceptOf » dans un fichier SKOS/RDF-XML valide » traite les fichiers contenant des « skos:Concept » ou des « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] ».
Il insère une propriété « skos:topConceptOf » au niveau de chaque concept qui n’a pas de propriété « skos:broader ».
n.b. : ne pas utiliser ce service pour les ressources non structurées ou faiblement structurées.
Ce service permet de remplacer les identifiants (URI) d’un fichier SKOS/RDF-XML par des identifiants ARK construits selon les préconisations de la California Digital Library (CDL).
Un identifiant ARK a la syntaxe suivante :
Le service « Attribuer des identifiants ARK à un fichier SKOS/RDF-XML valide » traite des fichiers contenant des « skos:Concept » ou des « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] ».
La transformation est effectuée en deux temps :
1- Remplacement de l’URI de la ressource (au niveau du schéma de concepts) par l’URI générique suivant : http://mon_site.fr/ark:/NAAN/ABC
L’ancien URI est mis dans une balise « dc:identifier ».
Au niveau des concepts, une suite alphanumérique de 8 caractères suivie d’un tiret puis d’un caractère de contrôle (check sum) vient compléter ce préfixe et constituer un identifiant ARK unique pour chaque concept de la ressource.
| Préfixe | Identifiant unique |
| http://mon_site.fr/ark:/NAAN/ABC | -CGT6ZZBQ-F |
2- Recalcul des URI pour :
Pour avoir des identifiants ARK conformes aux recommandations de la CDL (voir détails ici), l’URI générique doit être modifié comme suit :
Voici un exemple réel : http://data.loterre.fr/ark:/67375/1WB
A noter qu’en l’absence de NAAN, l’URI ne peut pas être considéré comme un « URI ARK » mais peut néanmoins être utilisé sans la partie ark:/NAAN/, la dernière partie étant un identifiant unique.
Différents modules de conversion sont proposés par Loterre :
Ce service permet de générer un fichier SKOS-XML à partir d’une feuille ce calcul (Excel, OpenOffice, etc.) sauvegardée en CSV.
Deux variantes de ce service sont proposées par Loterre, selon que le séparateur de champs présent dans le fichier CSV est un point-virgule ou une virgule :
n.b. : dans le cas d’un fichier CSV dont le séparateur est un point-virgule, utiliser les guillemets doubles anglais ( » / quote) comme délimiteur de texte pour les champs susceptibles de contenir le point-virgule comme ponctuation. Mettre les quotes au début et à la fin du texte pour que le point-virgule ne soit pas considéré comme un séparateur de champ. Si le texte contient lui-même des quotes, elles doivent être doublées.
La feuille de calcul initiale doit respecter un formalisme prédéfini :
| Donnée terminologique | Etiquette à utiliser xx = code ISO de la langue (*) |
Commentaire |
| Préférentiel | prefLabel_xx | Un « prefLabel_fr » est attendu |
| Synonyme | altLabel_xx | |
| Terme caché | hiddenLabel_xx | |
| Définition | definition_xx | |
| Note | note_xx | |
| Note d’application | scopeNote_xx | |
| Note éditoriale | editorialNote_xx | |
| Note historique | historyNote_xx | |
| Note de changement | changeNote_xx | |
| Exemple | example_xx | |
| Terme générique | broader_xx | Un « broader_fr » est attendu |
| Terme associé | related_xx | Un « related_fr » est attendu |
| Groupe (collection) | group_xx | Un « group_fr » est attendu |
| Alignement exact | exactMatch | |
| Alignement proche | closeMatch | |
| Alignement plus large | broadMatch | |
| Alignement plus restreint | narrowMatch | |
| Alignement associé | relatedMatch |
(*) Remplacer « xx » par le code langue ISO sur 2 caractères ; exemple « prefLabel_fr » pour le préférentiel français. Voir la liste des codes ISO 639-1
Les données sont transformées de la manière suivante :
De plus, la transformation insère également deux blocs au début du fichier SKOS/RDF-XML :
Le contenu textuel de ces champs devra être complété et validé par l’utilisateur.
Si les concepts n’ont pas d’identifiants, l’URI par défaut de la ressource est « http://www.monsite/vocabs/ABC ». C’est également la racine de l’URI des concepts, des relations et des éventuelles collections. Elle doit être remplacée comme suit :
Au niveau des concepts, l’URI est une concaténation de l’URI de la ressource avec un identifiant unique ; au niveau des collections, l’URI est une concaténation de l’URI de la ressource avec le nom du groupe en remplaçant les espaces par des « _ ».
Pour passer à des identifiants ARK, utiliser la transformation « Attribuer des identifiants ARK à un fichier SKOS/RDF-XML valide ».
Ce service permet de générer un fichier CSV à partir d’un fichier SKOS/RDF-XML valide contenant des éléments « skos:Concept » ou « rdf:Description[rdf:type[@rdf:resource=’http://www.w3.org/2004/02/skos/core#Concept’]] ».
Deux variantes en sont proposées par Loterre, selon la nature du séparateur de champs souhaités dans le fichier CSV résultant :
Le fichier produit peut être importé dans un tableur (Excel, LibreOffice, etc.) pour y être modifié (voir plus loin la procédure d’import dans Excel).
Les données sont transformées de la manière suivante :
Une première ligne « en-têtes de colonnes » est créée à partir des éléments (propriétés skos ou autres) utilisés pour décrire les différents concepts du fichier SKOS/RDF-XML :
Ensuite, une ligne est générée pour chaque concept du fichier :
A noter que :
Pour importer le fichier dans Excel :
Une fois modifié dans Excel, le fichier peut à nouveau être sauvegardé en CSV puis transformé en SKOS en utilisant le service « Transformer un fichier CSV dont le séparateur est un point-virgule en SKOS/RDF-XML » ou « Transformer un fichier CSV dont le séparateur est une virgule en SKOS/RDF-XML » en fonction du séparateur de champs appliqué au moment de la sauvegarde.
Ce service permet de générer un fichier HTML (version française) à partir d’un fichier SKOS valide. Il traite des fichiers contenant des « skos:Concept » ou des « rdf:Description » de type « Concept ».
Deux variantes en sont proposées par Loterre, selon la version linguistique choisie :
Les entrées terminologiques sont présentées dans l’ordre alphabétique du préférentiel (français ou anglais) :
La richesse des informations affichées dépendra du contenu et de la structuration du fichier SKOS de départ.
Cette transformation permet de générer un fichier PDF à partir d’un fichier SKOS valide.
Deux variantes en sont proposées par Loterre, selon la version linguistique choisie pour la ressource :
Plusieurs sections sont produites en fonction du contenu et de la structuration du fichier :
Des pages additionnelles sont insérées :
A noter que les pages de couverture peuvent être remplacées en éditant le fichier final avec un éditeur PDF comme PDF Sam Basic.
Le service « Télécharger » permet un téléchargement de l’intégralité du contenu de l’une des ressources exposées dans Loterre, sous différents formats : PDF, CSV, SKOS/XML ou JSON-LD
Dans la plateforme Loterre il est également possible :
Les terminologies proposées par des tiers font l’objet d’un examen fondé sur des critères de qualité et de format. Les propriétaires du site Loterre se réservent le droit d’opérer une modération des propositions reçues. Ils peuvent refuser d’intégrer une terminologie s’ils considèrent qu’elle ne répond pas aux critères qui régissent la plateforme.
Les terminologies intégrées au triplestore sont exprimées selon un modèle de type « SKOS étendu », qui associe au standard SKOS un certain nombre de catégories appartenant à d’autres formats ou langages (SKOS-XL, Dublin Core, Isothes, OWL, RDFS, etc.).

Ontologie de Loterre (cliquer sur l’image pour la réduire)
La couverture scientifique des terminologies exposées dans Loterre est multidisciplinaire et doit relever d’un ou plusieurs des domaines scientifiques suivants :
Les ressources exposées dans Loterre doivent disposer d’une licence autorisant la mise à disposition et la réutilisation des données, de type :
Les terminologies exposées dans Loterre peuvent :
Les possibilités d’affichage et de recherche dans une langue donnée sont liées aux caractéristiques des applicatifs d’exposition/interrogation connectés au triplestore.
Les ressources terminologiques intégrées dans Loterre se veulent, autant que possible, conformes aux bonnes pratiques du W3C relatives à la publication de données liées.
Idéalement, elles doivent respecter les critères alloués aux données « 5 étoiles » : Linked Data – Design Issues
Schématiquement, elles peuvent être du type :
Les données de type ressources lexicales, ressources d’analyse de contenu ou ontologies ne pourront être intégrées à Loterre que si elles sont converties en format SKOS, ce qui peut entraîner une perte d’informations par rapport au contenu d’origine.
Du point de vue de leur structuration, elles peuvent :
L’architecture de Loterre s’appuie sur un triplestore (base de triplets) doté d’un outil de consultation humaine et interrogeable via une interface SPARQL et une API.
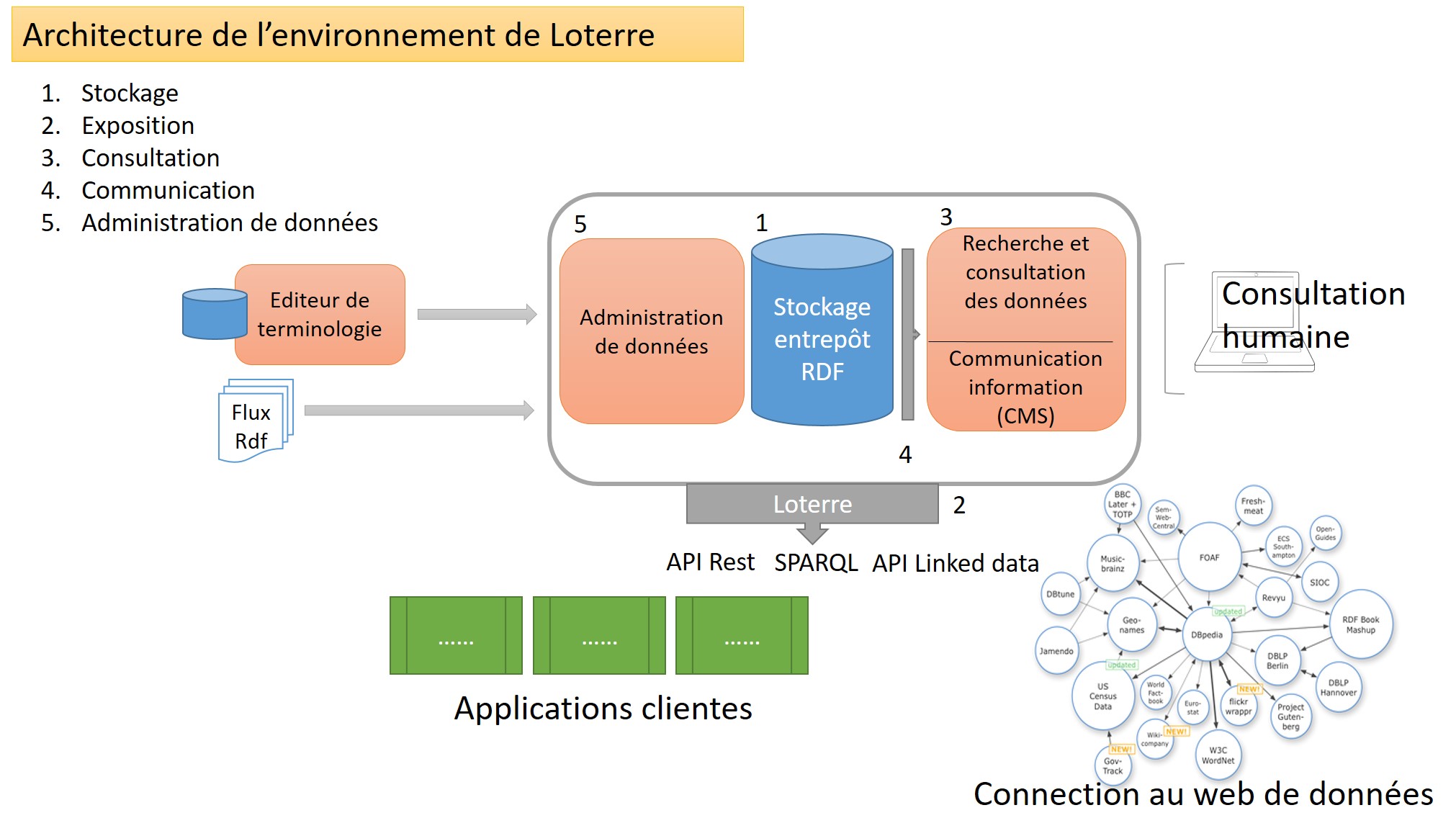
Pour offrir à ses utilisateurs un accès aux terminologies, Loterre fait appel à divers outils tiers open-source :
Loterre a été conçu par l’Inist-CNRS
Une de vos questions est restée sans réponse ? Posez-la en direct, via le formulaire de contact